
Videos from research into robust contact methods for robotics
This video demonstrates the effectiveness of one of my contact methods for the problem of a simulated manipulator grasping a tennis ball. This task is notoriously difficult to simulate, and few contact methods are capable of doing so; my method does so in O(n3), which is faster than any other known method.
The only other example of physically simulated grasping is Miller's excellent GraspIt! software; that software uses a contact method specially developed for grasping, while my method is general purpose (grasping, locomotion, and more). Miller's method exhibits worst-case exponential time complexity and expected-case O(n4) time in the number of contact points.
The video shows a manipulator arm grasping a ball while moving along
a sinusoidal trajectory.

Videos from my advanced penalty method for rigid body simulation
Reduction of oscillation
This video shows how the advanced penalty method is able to avoid the oscillations that plague the standard penalty method. The cube is placed such that it penetrates the ground plane, and then the penalty method is applied. Notice that the cube is pressed straight upward, along the direction of the contact normal.
 Before the penalty method is applied. |
 A short time after the penalty method is applied. |
Ability to handle piles of objects
Piles and stacks of objects are problematic for most contact methods. This video shows a stable state of a pile of objects of different shapes and masses inside a box. As can be seen from the video, the objects are resting without movement.

Videos from research into the Task Matrix
Robots used in the videos

The simulated robots used in videos. Note that the layouts of
the degrees-of-freedom are quite different; for example, the
simulated Asimo employs five DOF in the arm while the mannequin
uses six. Additionally, the heights of the two robots are
quite different.
Waving
The following two movies show Asimo and the mannequin waving using a "canned" (i.e., free-space movement) task program.
 |
 |
NEW! Physically embodied Asimo waving:
 |
Fixating
Videos showing both robots focusing their gaze on moving objects. fixate obviously works on unmoving targets as well. Note that the fixate program attempts to use the degrees-of-freedom of both the base orientation and the neck; if not possible (e.g., the base DOF are currently being used for reaching), only the DOF for the neck are used.

Asimo focusing its gaze on a rolling tennis ball. |
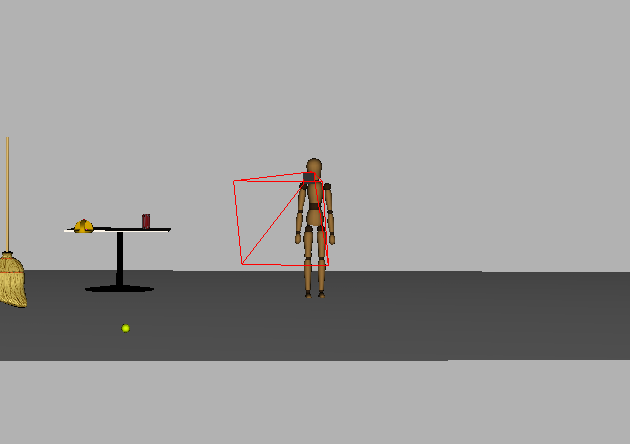
The mannequin focusing its gaze on a rolling tennis ball. |

Asimo fixating on another, walking Asimo. |

The mannequin fixating on a walking Asimo. |
NEW! Physically embodied Asimo fixating on a wine flute (augmented with a marker to aid in object recognition). The goal of the task is to keep the cup centered in Asimo's camera display. The movie on the right shows Asimo's viewpoint:

|

|
Pointing
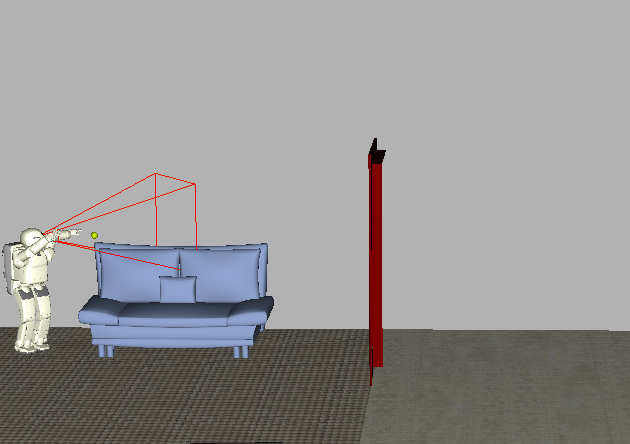
Pointing is a sophisticated behavior that conveys intention, trains the sensors, and is useful for communication. The video on the left shows the simulated robot pointing (one arm points while the other trains an arm-mounted camera on the target), and the video on the right shows the physically embodied robot pointing; the object to be pointed to is a wine flute (augmented with a marker to facilitate recognition).

|

|
Reaching
Reaching is used to prepare the robot to grasp an object. Multiple valid pregrasping configurations for the hand may be specified to address the scenario when one or more configurations is unreachable.
"Interactive" reaches are shown below. Each time the robot reaches to the tennis ball, it is moved to a new location. This video shows that motion-planning is used (in real-time) to navigate around obstacles. See [1] and [2].
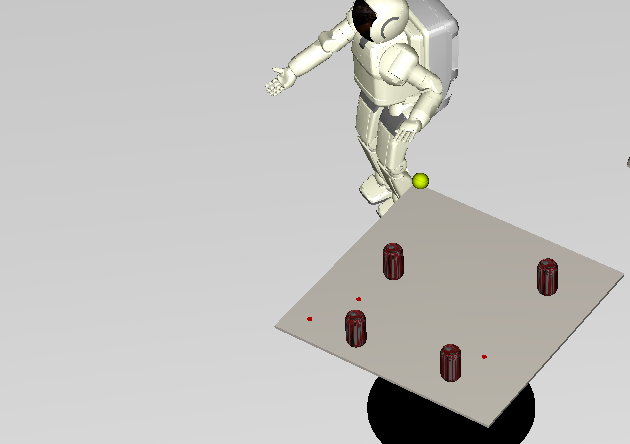
|
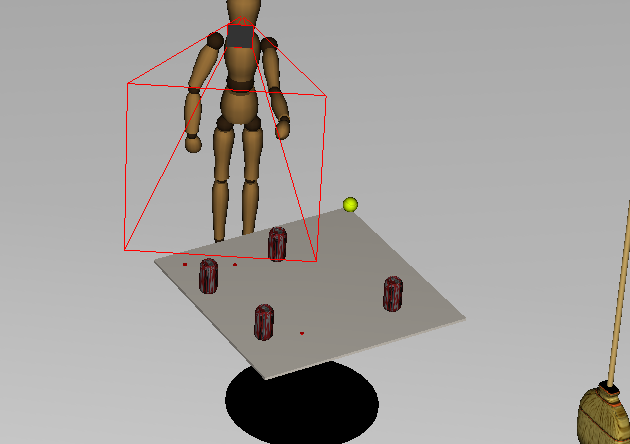
|
NEW! Physically simulated Asimo reaching (to 15cm) away to a wine flute. We are currently getting this behavior working on the robot.
 |
Grasping
Videos showing Asimo grasping a couple of objects. No videos of the mannequin are shown grasping; see [3] for explanation.
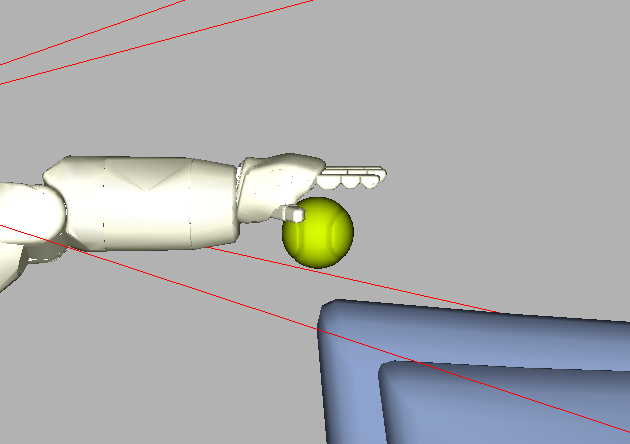 |
 |
Releasing
A video showing Asimo releasing a grasped object. No videos of the mannequin are shown grasping; see [3] for explanation.
 |
Exploring the environment
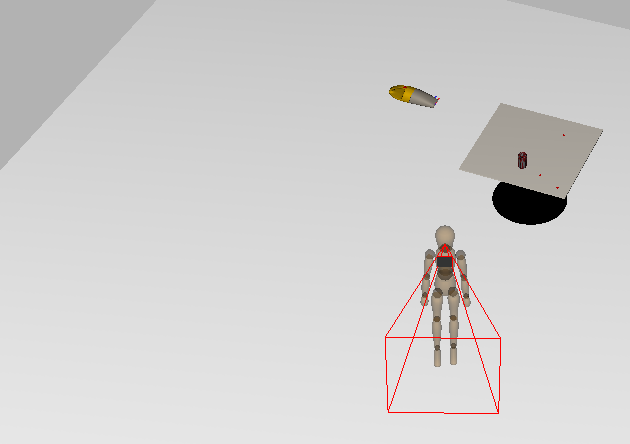
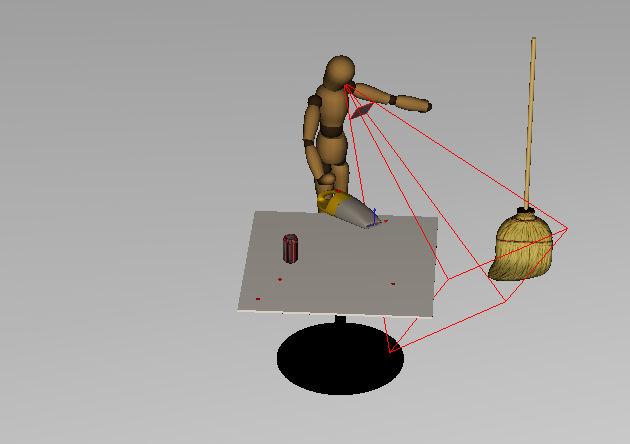
The Task Matrix utilizes a passive sensing model to allow task programs to query the environment. The model of the environment is typically kept updated by fixating on manipulated objects, but the model must be constructed to map object locations for manipulation and collision avoidance. The explore task program performs such an initial construction.
The videos below, which were constructed in a time-lapse manner, show the environment being modeled using the robots' simulated sensor (the red tetrahedron-like wireframe emanating from the robots' heads). When the sensor models part of a surface, a brown texture appears on that surface.

|
|
Picking up an object
We constructed a complex behavior for picking up an object using three primitive task programs: reach, grasp, and fixate. The robot fixates on the target object while simultaneously planning how to reach to it. After planning is complete, the robot reaches to the object while simultaneously still attempting to fixate on it. When the object is graspable, the robot grasps it, which also terminates the fixate program. See [1], [2], and [3] for more information.
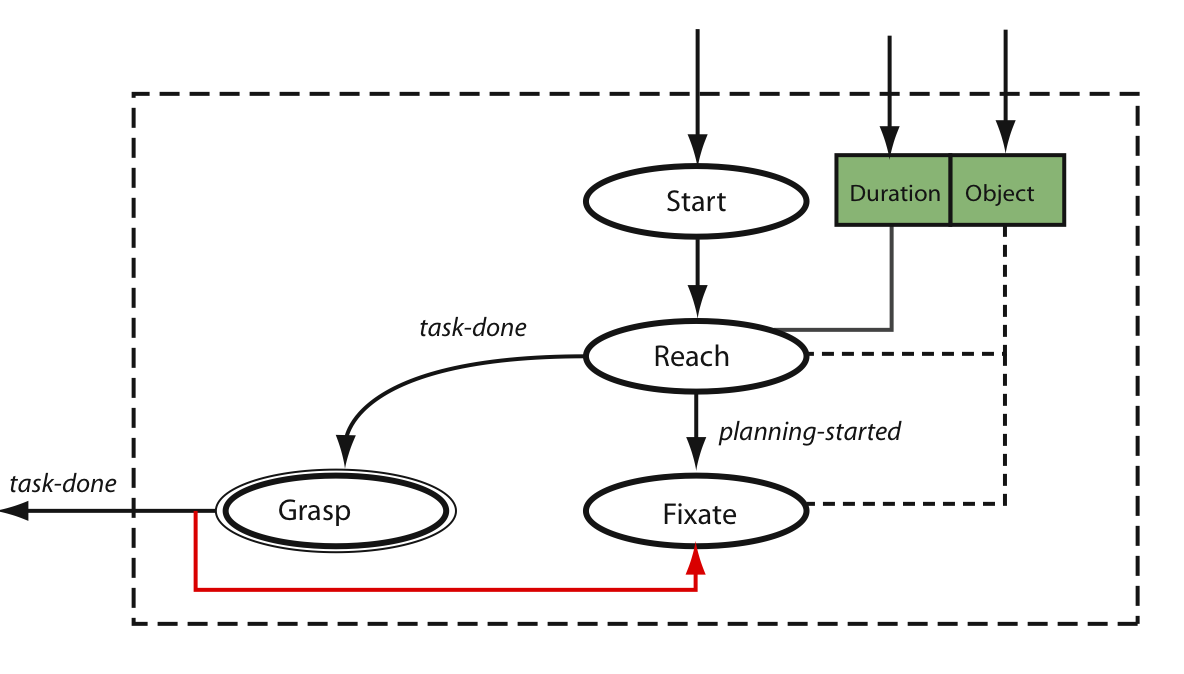
The state machine for performing the pickup behavior. |
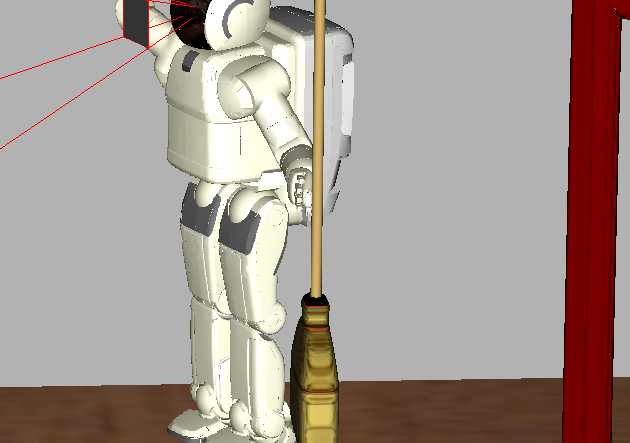
Asimo picking up a tennis ball. |

Asimo picking up a vacuum. |

The mannequin picking up a vacuum. See [3] for more information. |
Putting down an object
The putdown task program is analogous to pickup; it uses position, release, and fixate to place an object onto a surface. However, there are a couple of significant differences. Putdown uses two conditions, near and above, to determine valid operational-space configurations to place the target object. Second, the fixate subprogram focuses on the surface rather than the grasped object.
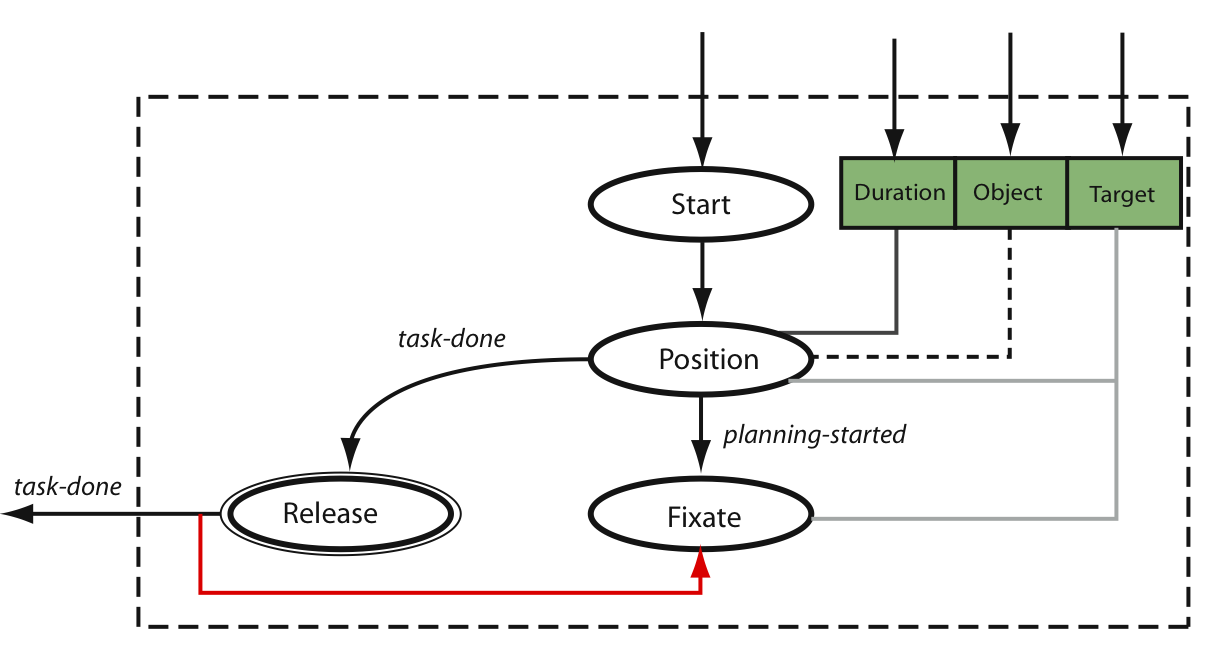
The state machine for performing the putdown behavior. |

Asimo placing a tennis ball on a table. |
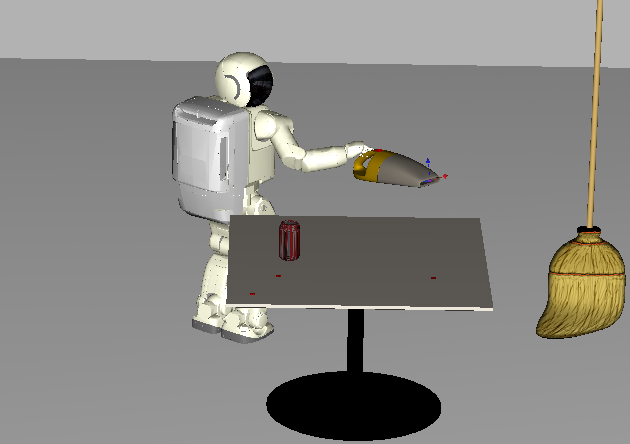
Asimo placing a vacuum on a table. |
The mannequin placing a vacuum on a table. |
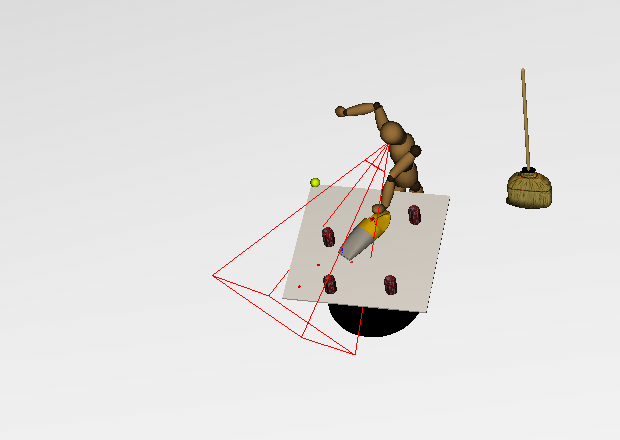
Vacuuming a region of the environment
The vacuum program is a complex task program consisting not only of the primitive task programs position and fixate, but also of the complex task programs pickup and putdown. It commands the robot to pickup a vacuum, vacuum a region of the environment, and put the vacuum down when complete. The position subprogram uses the above condition to guide the tip of the vacuum above the debris to be vacuumed. See [1], [2], and [3] for information on video artifacts.
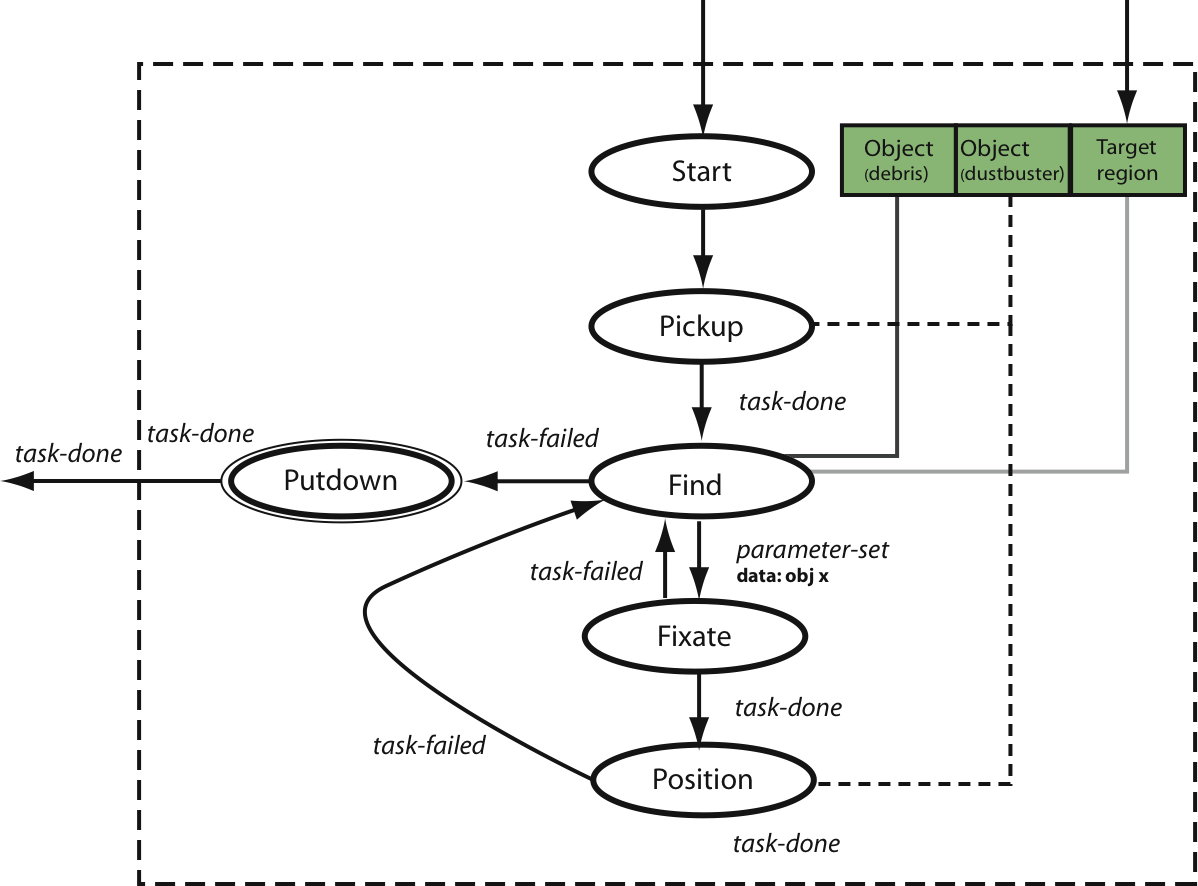
The state machine for performing the vacuuming behavior. |
|

|
|
Greeting a humanoid
The greet behavior is a complex task program composed of the primitive subprogram fixate and programs for preparing to wave (i.e., a postural task program) and waving (i.e., a canned task program). Greet first focuses the robot's gaze on the target humanoid. When it has focused completely, it brings the arm up and begins waving. When waving is complete, the robot reverts to a rest posture and stops tracking the target robot. See [1] for information on video artifacts.
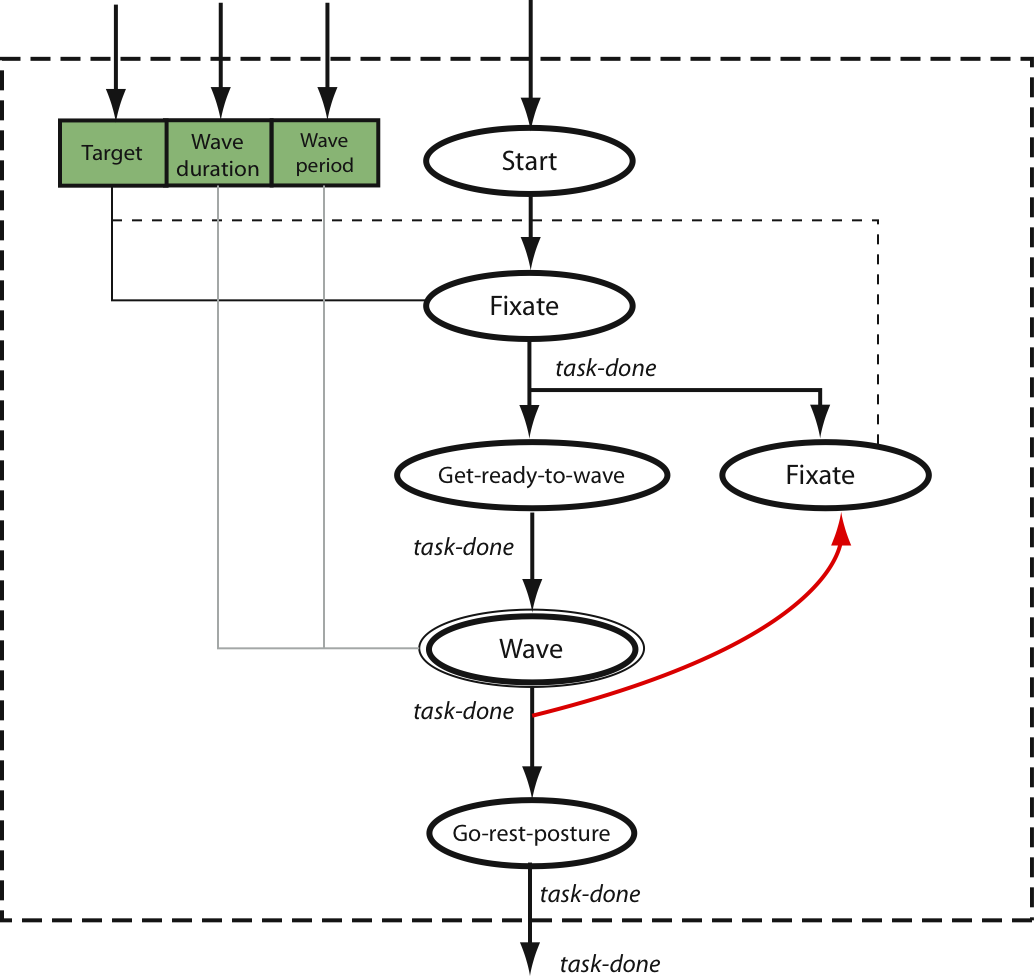
The state machine for performing the greeting behavior. |
|
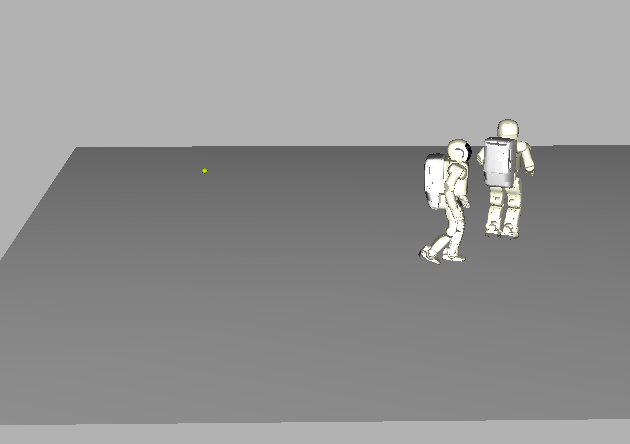
Asimo greeting a fellow, walking Asimo. |
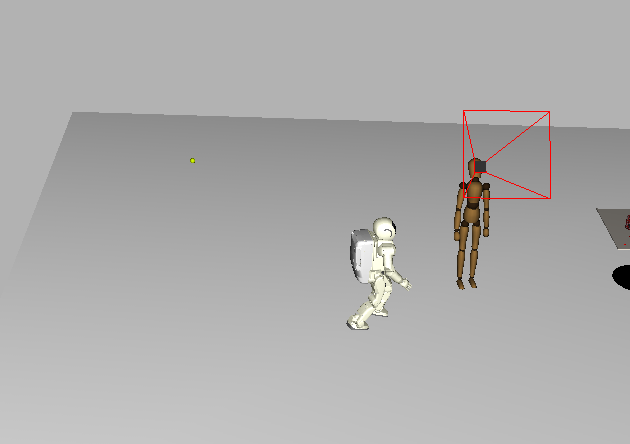
The mannequin greeting a walking Asimo. |
Notes on Task Matrix videos
[1] The robots in these videos are kinematically simulated. As a result, locomotion is depicted in an unsophisticated manner (sliding across the floor rather than walking). Note, however, that an implementation on a physically simulated or true humanoid robot will not require any porting to get the task programs using locomotion to function properly; locomotion in the Task Matrix is accomplished abstractly by giving planar position and orientation commands to the robot base.
[2] The movement shown in these videos is often not hominine. This is a result of our implementation of the underlying algorithms that drive the robot. It is possible to produce more human-like movement by altering these inverse kinematics and motion-planning algorithms, without affecting the task programs in any way.
[3] The mannequin has no fingers. Thus, we simulate an electromagnetic mechanism for grasping objects; the objects are affixed directly to the mannequin's hand. However, this mechanism makes for uninteresting videos of the grasp and release task programs.
