|
|
||||
| Home | Publications | Miscellaneous | Personal Details | |
|---|---|---|---|---|
|
|
||||
| Home | Publications | Miscellaneous | Personal Details | |
|---|---|---|---|---|
|
Project:
|
|---|
This project looks at developing general
adaptive capabilities
in robots and
multi-robot systems.
By general capabilities we mean capabilities
that perform well over a range of tasks and environments. Such capabilities go
further than specialized skills in increasing the autonomy and applicability of
robotic systems.
One form of general adaptivity is spatio-temporal adaptivity. This project uses
reinforcement learning
to allowing robots to dynamically adjust their behavior to any given environment
while performing a set task.
To best demonstrate how the structure of a group of robots can adapt, we look at
transportation, where a group of robots have to traverse an environment
between a source and a sink. Transportation is a sub-problem of
foraging
in that the positions of the sources and sinks are known, eliminating issues of
search. The simplicity of transportation makes it easier to show that
the improvements in the group performance are due to a change in the groups
spatio-temporal structure.
The controllers we use for the robots are
behavior-based.
The robots used in the experiment below had three different abstract,
high-level behaviors: direct target approach, wall following,
and stopping. By learning how to relate different input states to any
of these three behaviors, the robots can improve their performance. On top of
the movement behaviors we implemented a concurrent set of communication
behaviors for cooperation. The communication strategies are described in a
separate section below.
The three high-level movement behaviors take care of lower level tasks such as
obstacle avoidance, position estimation, and keeping track of what target to
visit next, the source or the sink.
The input space is made up of several highly abstracted virtual sensors. In the
experiment we describe below we used a five bit input vector. The first bit
indicated the presence of a visible target. The second bit was on for a
relatively short amount of time at random intervals, providing an unbiased
fragmentation of the input state. The three final bits reflected the presence
of the three colors used for the color markings. They only reported on the
markings on the closest of the visible robots.
The robots received a reward on arrival at a target, source or sink. The reward,
r, was inversely proportional to the traversal time, t, and
relative to the optimal traversal time, to:
r=1+(to/t).
The improvements were due to both spatial and temporal reorganization. The
robots learned to follow a circular path, minimizing interference. They also
learned to stop when they saw other robots approaching, i.e. they did not see
their yellow markings.
Adaptive Spatio-Temporal Organization in Multi-Robot Systems
Research Objectives
Transportation - An Initial Problem Domain
Controller Architecture
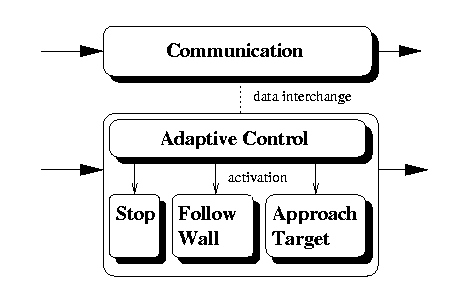
The Adaptive Control Algorithm
The adaptive element of the controller uses
reinforcement learning
to relate the different input states to the available movement behaviors. The
reinforcement learning
uses a naive Q(λ) algorithm with an accumulative eligibility trace and a
Boltzmann Softmax action selection algorithm.
Cooperative Strategies
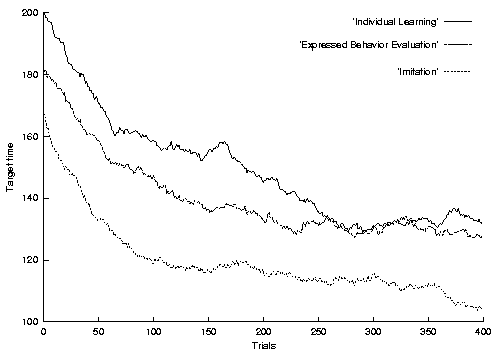
To improve the learning rate of the group we developed two communication
strategies based on language-less communication in animals and humans. The first
strategy was called expressed behavior evaluation and the second
imitation. In order to scale to large groups, the strategies only used
local communication.
The expressed behavior evaluation strategy was inspired by wordless
calls of encouragement or warning in humans and animals. Humans and some animals
can recognize the active behavior in others and estimate their input state. This
is very difficult to achieve in robots, so our robots broadcast locally every
new state-action pair they went through. When a robot received a state-action
message referring to a Q-table entry with an exceptional value in the robot's
own Q-table, the robot would send a feedback message to the originator of the
state-action message. On reception of a feedback message, a robot would assume
that its current state and action was an exceptional combination and update its
Q-table accordingly.
The imitation strategy was inspired by
imitation learning
where a student repeats the actions of a teacher, hence experiencing the same
state-action chains and receiving similar reward. In our system this is
implemented as storing and broadcasting locally the eligibility trace that lead
to the highest reward. Similar cooperation strategies have been shown to work
in a grid-world, pursuit domain by Ming Tan. Our results show that the same
improvements in learning rate can be achieved in more realistic simulations.
Experiments
As an initial demonstration of spatio-temporal adaptation, we did a series of
experiments where five
Pioneer 2DX robots
simulated using
Player and Stage
, had to traverse a 6-by-7 meter rectangle containing a source and a sink on
opposite short sides. The robots were equipped with PTZ cameras and SICK laser
range finders. The robots also wore color markings emphasizing their orientation
with red on the left side, green on the right, and yellow at the rear.

Results
Our experiments demonstrated statistically significant improvements in both
individual and group performance. They also demonstrated the value of our
cooperative strategies. Below a graph illustrates the performances of the three
different learning strategies.
Publications
Support
The project is
funded in part by the Deparment of Energy (DOE), Robotics and
Intellgent Machines (RIM), grant number
DE-FG03-01ER45905, for "Multi-Robot Learning in Tightly-Coupled, Inherently
Cooperative Tasks", and in part by the Office of Naval Research (ONR), Defence
University Reseach Instrumentation Program (DURIP), grant number
00014-00-1-0638 for "Equipment Support for Dynamic Adaptive Wireless Networks
with Autonomous Robot Nodes".
Return to the
Interaction Lab,
the
Robotics and Embedded Systems Lab,
or the
USC Robotics Research Lab.
by
Torbjørn S Dahl.